In Linux, the users download the file of various packages to perform specific operations, i.e., install specific packages, download the source code or executables, etc. Linux being a versatile command line platform, offers numerous utilities, i.e., wget, curl to download the file from the URL. This post will demonstrate several methods to download a file using URLs in Linux. The post’s content is below:
- How to Download a File Via wget Command in Linux?
- Example 1: Download a Single File
- Example 2: Download and Save the File With Another Name
- Example 3: Download the Interrupted File
- Example 4: Download the Multiple Files
- Example 5: Download a File in Specific Directory
- How to Download a File Using URL Via curl Command?
- How to Install curl in Linux?
- Example 1: Download and Save the File
- Example 2: Download the File With the New File name
- Example 3: Download the Interrupted File
How to Download a File Via wget Command in Linux?
The “wget” command is used for downloading files from the website. The “wget” command supports the FTP, HTTP, and HTTPS protocols.
The working of the wget command depends on its basic syntax, which is mentioned below:
Syntax:
$ wget [option] [URL]
The “wget” is the main keyword in the syntax. However, the square bracket shows the “options” of the “wget” command, and the last parameter is “URL”, where files are located.
The “wget” command supports a list of essential options that can get by utilizing the “help” command:
$ wget --help
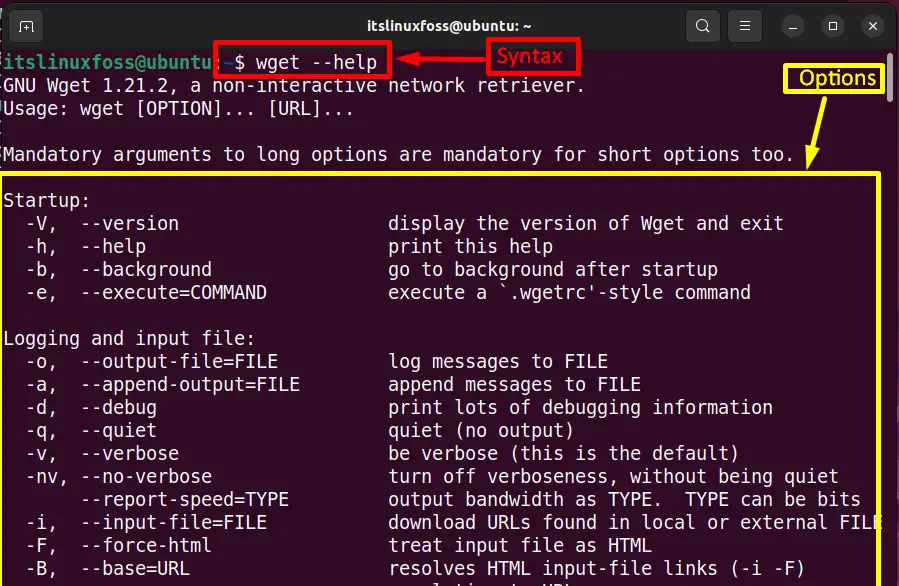
Next, move to the next section that describes the working of the wget command.
Let’s move on to the first example.
Example 1: Download a Single File
The “wget” command, without any option, simply downloads the single file. For example, the following “wget” command with the URL of the specific file will download a single file:
$ wget https://openrgb.org/releases/release_0.7/OpenRGB_0.7_x86_64_6128731.AppImage
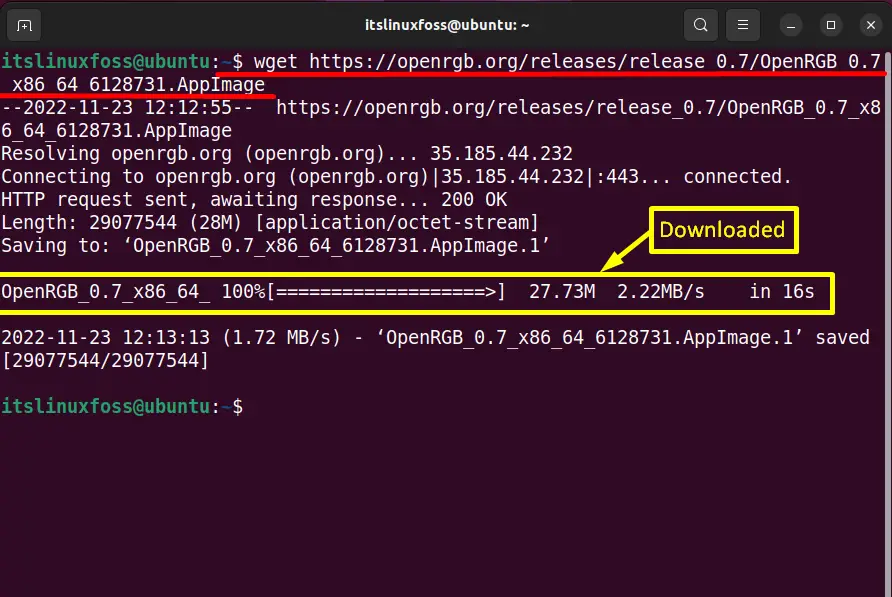
The “wget” displays the progress bar verifies that the current file is successfully downloaded in the entire “home” directory.
Example 2: Download and Save the File With Another Name
The downloaded file from the website will be saved with the actual name as in the URL by default. But it can be edited using the “-o” option of the “wget” command. Suppose, in the current situation, execute the “wget -o” command and then type the new file name and the URL of the file as shown below:
$ wget -O file1 https://wordpress.org/latest.zip
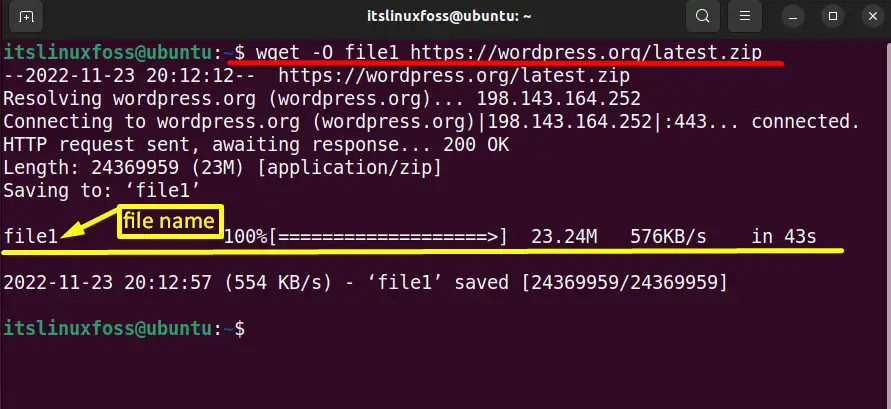
The downloaded “wordpress.org” file has been saved as “file1” in the entire home directory.
Example 3: Download the Interrupted File
Sometimes, during the downloading of large files, the internet connection drops, and the downloading process will be stopped such as:
$ wget http://downloads.asterisk.org/pub/telephony/asterisk/asterisk-16-current.tar.gz
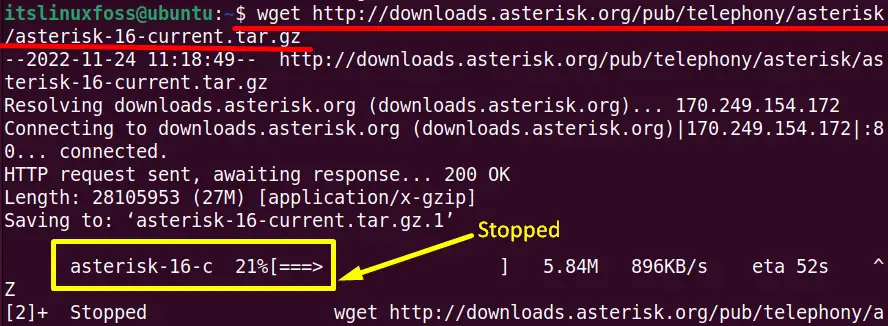
In such a situation, the wget command with “-c” options supports the users to download the resumed file. To do this task, type the “wget -c” command with the URL of the interrupted file:
$ wget -c http://downloads.asterisk.org/pub/telephony/asterisk/asterisk-16-current.tar.gz
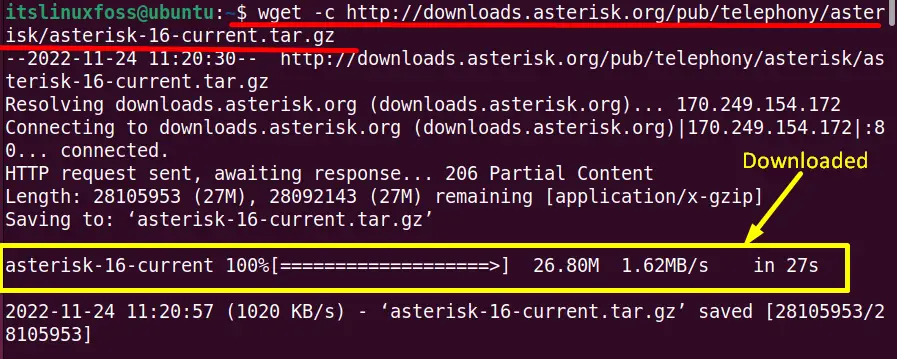
The output displays that the “wget -c” command will resume the interrupted file from where it stops and complete its downloading.
Example 4: Download the Multiple Files
The “-i” option of the “wget” command can download more than one file using a URL. Suppose in the “File.txt” file there are two URLs as shown in the screenshot:
$ cat File.txt

Now enter the “wget -i” command, and after that, type the file name “File.txt” on the terminal:
$ wget -i File.txt
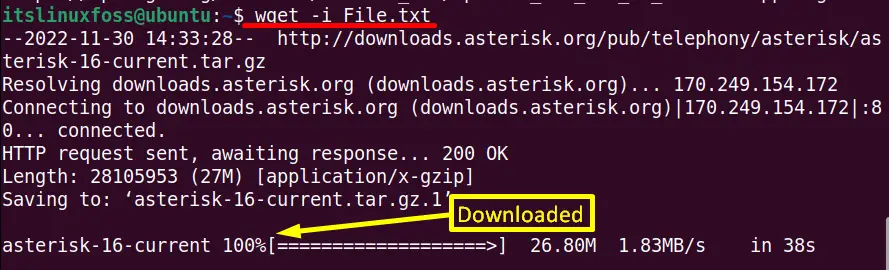
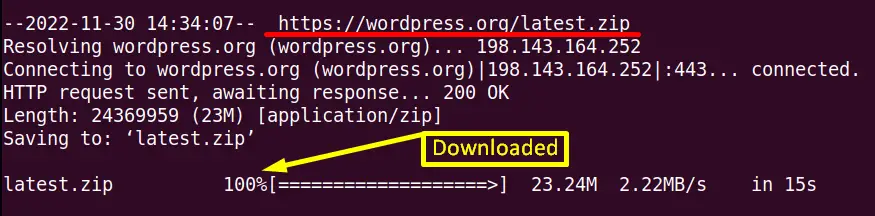
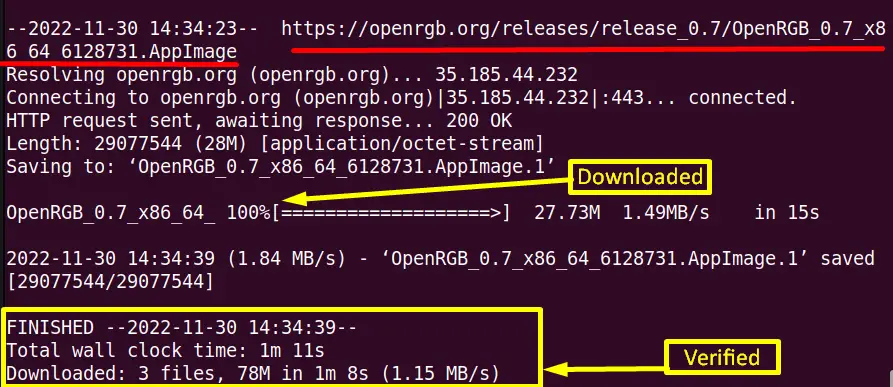
Here, the above output shows that all the files present in the “File.txt” file are successfully downloaded.
Example 5: Download a File in Specific Directory
The “wget” command supports the “-P” option that helps to download the file in a specific directory. To perform this operation, type the “wget -p” command with the desired path and URL:
$ wget -P ~/Downloads https://github.com/rustdesk/rustdesk/releases/download/1.1.9/rustdesk-1.1.9.deb
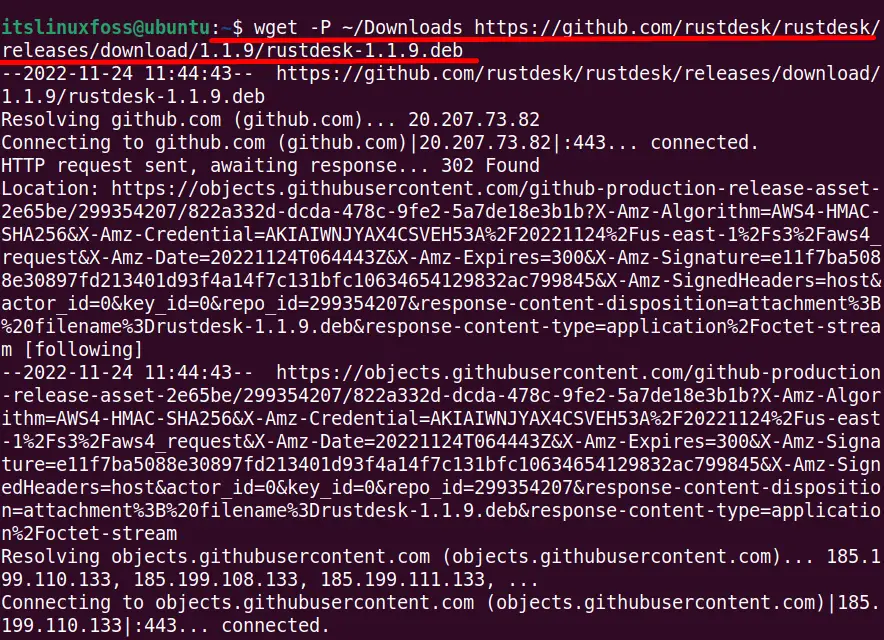
$ ls -l Downloads

The above output confirms that the current file is downloaded from the mentioned “Downloads” directory.
How to Download a File Using URL Via curl Command?
The curl command is the command line utility that downloads the files from the server or to the server. Same as the “wget” command, it supports a large list of majorly used protocols like “HTTP”, “HTTPS”, “RTSP”, “FTP”, “FTPS”, and much more.
How to Install curl in Linux?
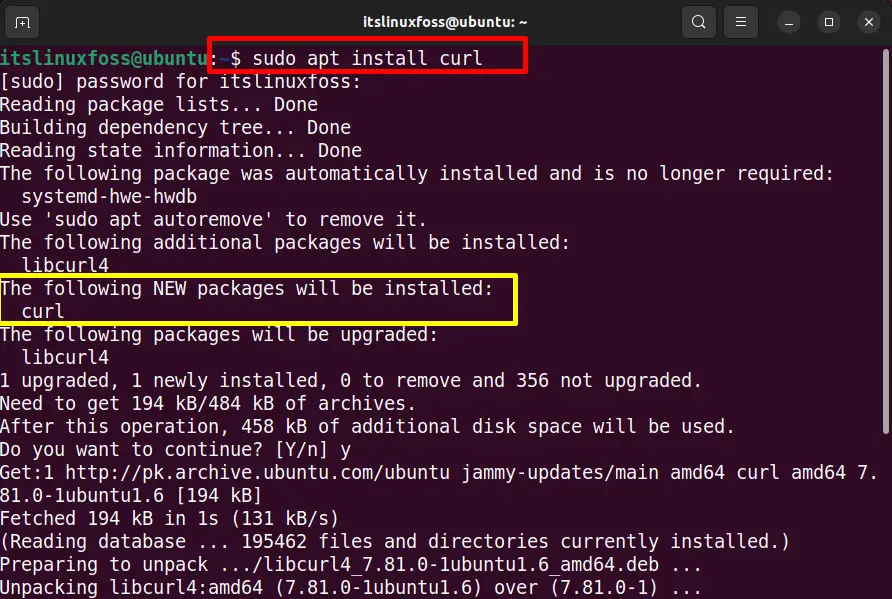
The “curl” command is installed on Linux by default. However, it is not installed in some Linux distributions like Ubuntu 22.04. To install “curl” in Ubuntu 22.04, run the “apt install curl” command in the terminal:
$ sudo apt install curl
To install it on other Linux distros, use the below-stated command:
For Fedora/CentOS/RedHat:
$ sudo yum install curl
For openSUSE:
$ sudo zypper install curl
Syntax:
The general syntax of the curl command is written below:
curl [option] [URL…]
In the above syntax, the “curl” is the main keyword, and the square brackets represent the supported “option” and the “URL” of the specific file.
Enter the curl “help” command on the terminal to get the list of its supported options:
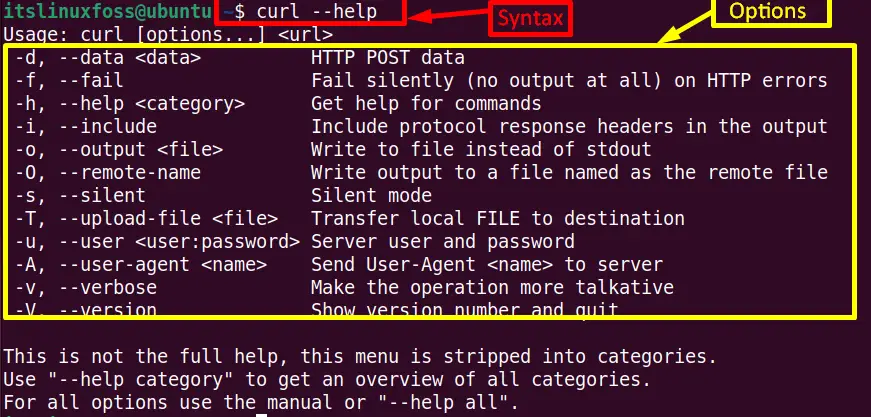
This “curl” command is the short form of “Client URL”. As its basic description shows that it is beneficial for downloading files using URLs. This section comprises some practical examples to explain the procedure of how to download files via “curl” commands.
Furthermore, it also describes various examples of its supported options.
So Let’s head over the examples.
Example 1: Download and Save the File
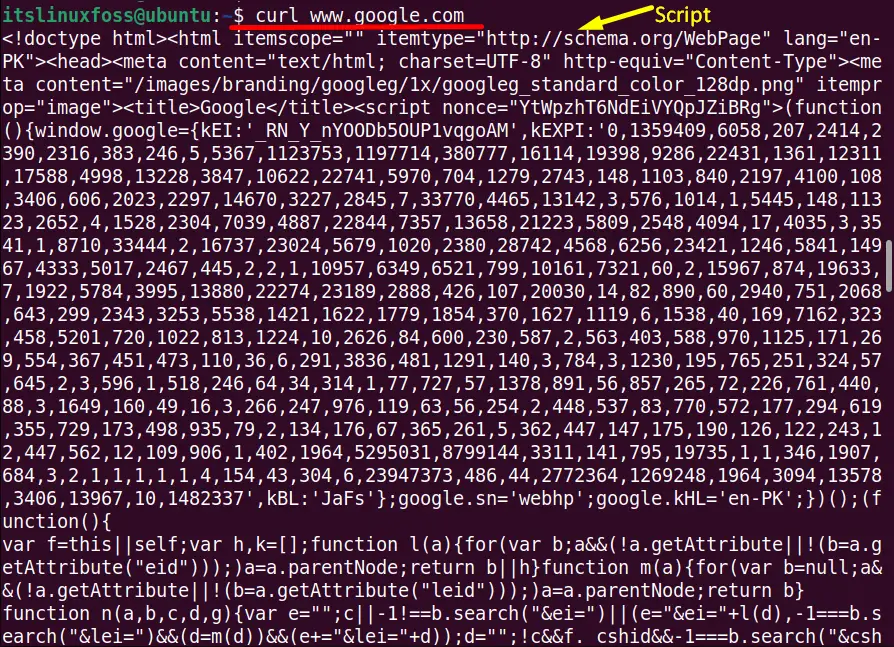
The simple “curl” command with the particular URL displays the script of that file as shown in the below screenshot:
$ curl www.google.com
However, if we use the “-O” option with the “curl” command, then it will completely download the desired file. Here the “curl – O” command is written below to perform this task:
$ curl -O http://downloads.asterisk.org/pub/telephony/asterisk/asterisk-16-current.tar.gz

The output verifies that the required file is fully downloaded now.
Tip: For downloading multiple files using the “curl” command, follow the below-given syntax:
$ curl -O https://wordpress.org/latest.zip -O http://downloads.asterisk.org/pub/telephony/asterisk/asterisk-16-current.tar.gz
Example 2: Download the File With the New File Name
In the above example “-O” in the UPPER case is used to download the file with the same file name. However, in this example, the “-o” in lowercase is useful for downloading and saving the file with the new name, such as “FirstFile”. Enter the below-written command on the terminal:
$ curl -o FirstFile https://wordpress.org/latest.zip

The output displays the file that has been downloaded and also shows the total space occupied by the downloaded file, the current speed, total time, and much more about that file.
Next, run the “ls -l” command to verify the newly downloaded file:
$ ls -l FirstFile

At this point, it is verified by the output that the downloaded file is saved as the “FirstFile” name.
Example 3: Download the Interrupted File
The “curl” command provides another option, “-C”. Its purpose is to resume the downloading process of the current file, which was paused or interrupted due to some other reasons. The user can also cause the interrupt while downloading by pressing the shortcut key “Ctrl+Z”. In our case, a large file was downloaded. The internet connection breaks, then the process will be stopped:
$ curl -O http://downloads.asterisk.org/pub/telephony/asterisk/asterisk-16-current.tar.gz

To resume the downloading process executes the “curl – C” command on the terminal:
$ curl -L -O -C - http://downloads.asterisk.org/pub/telephony/asterisk/asterisk-16-current.tar.gz
The entire file starts downloading from the point of the interruption.

The percentage identifies that it has been downloaded.
Conclusion
The files can be downloaded using the URL through the “wget” command. The generalized syntax of the “wget” command is “wget [option] [URL] “. In addition, it can also be done with the usage of the “curl” command. Its general syntax is “curl [option] [URL…]”. Both commands provide essential options to get the desired output. In this post, the “wget” and the “curl” commands are described in detail. Moreover, this post also explains these commands’ basics, usage, and working.
