The built-in “sed” command is also known as the “stream editor” used for text manipulation, i.e., insertion, deletion, substitution, or replacement. This utility performs the operations quickly on the files without opening them in the text editor like vim, nano, and many others.
Apart from its basic functionality, it also uses regular expressions that help in complex pattern/character matching, like sed ‘s/\s\s*/ /g’ for matching more than one whitespace character.
This post explains the working of the sed ‘s/\s\s*/ /g’ in Linux:
- How Does the sed ‘s/\s\s*/ /g’ Command Work?
- Alternative 1: sed ‘s/[[:space:]][[:space:]]*/ /g’ Command
- Alternative 2: sed ‘s/[[:space:]]\{1,\}/ /g’ Command
How Does the sed ‘s/\s\s*/ /g’ Command Work?
The sed ‘s/\s\s*/ /g‘ command searches the consecutive whitespaces from the text and replaces them with a single whitespace. The regular expression ‘s/\s\s*/ /g‘ used in the “sed” command is described here:
- The “s/” stands for a “substitute” that matches mentioned character/pattern occurrences from the text.
- The “\s” comes from the Perl regular expression, which matches the single horizontal or vertical whitespace character. It is an alternative to the POSIX expression [[:space:]].
- The “\s*” searches the consecutive whitespaces character, i.e., more than once.
- The “/ ” corresponds to the single whitespace replacing consecutive whitespaces.
- The “/g” refers to a “global” that replaces the particular character/pattern in the text.
Example:
A “SampleFile.txt” is taken as an example having one line content that is displayed using the “cat” command:
$ cat SampleFile.txt
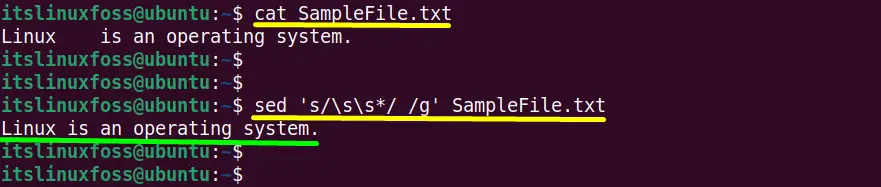
The content of “SampleFile.txt” has more than one whitespace character between the “Linux” and “is” strings.
Execute the sed ‘s/\s\s*/ /g’ command to remove this consecutive whitespaces character from the desired file:
$ sed 's/\s\s*/ /g' SampleFile.txt

The consecutive whitespaces characters have been replaced by a single whitespace.
Alternative 1: sed ‘s/[[:space:]][[:space:]]*/ /g’ Command
The “\s\s*” regular expression of the “sed” command can also be replaced with the POSIX expression [[:space:]][[:space:]]*. It also performs the same job as “\s\s*”, i.e., replaces consecutive whitespaces characters with a single whitespace.
Let’s see its practical implementation:
$ sed 's/[[:space:]][[:space:]]*/ /g' SampleFile.txt
In the above command the “[[:space:]]” searches the single whitespace/tab and the [[:space:]]* searches for the consecutive whitespaces and tabs:

The same output has been displayed as the “\s\s*” regular expression.
Alternative 2: sed ‘s/[[:space:]]\{1,\}/ /g’ Command
The “[[:space:]]\{1,\}” is another alternative of the sed ‘s/\s\s*/ /g’ command. In this regular expression the “ [[:space:]]” means a [[:blank:]], i.e, nothing. On the other hand, the “\{1,\}” denotes one or more than one whitespace character.
Use this [[:space:]]\{1,\} regular expression of the “sed” command for the removal of more than one whitespaces character from “SampleFile.txt”:
$ sed 's/[[:space:]]\{1,\}/ /g' SampleFile.txt

The above command has been removed the consecutive whitespaces from the “Samplefile.txt”.
Conclusion
In Linux, the sed Command: sed ‘s/\s\s*/ /g’ allows the users to replace more than one whitespace character or tab with a single whitespace globally. It matches all the consecutive whitespace characters until no more matches are made in that particular text file.
This post has provided a detailed view of sed Command: sed ‘s/\s\s*/ /g’ and its practical implementation.
