While working in Linux, there’s a good chance for you to encounter a text file containing massive data. Most of the time, the data isn’t sorted, and there are repetitions. Linux has several useful command-line utilities that help its users do their work more efficiently than other operating systems. One is the “uniq” command, which detects and deletes duplicate entries in the data, or you can use it to filter records.
This article will explain the working and usage of the uniq command in Linux. The post’s content is as follows:
- What is uniq Command in Linux?
- How to Use the uniq Command in Linux?
- Example 1: Count the Number of Repeated Lines Using uniq
- Example 2: View Only the Repeated Lines Using uniq
- Example 3: View Unique Lines Ignoring Case Sensitivity
- Example 4: View Non-Repeated Lines
- Example 5: Skip Fields to Filter Duplicate Lines
- Example 6: Skip Characters to Filter Duplicate Lines
What is uniq Command in Linux?
The basic purpose of the uniq command is to sort the data and remove the repeated lines so that no ambiguity can be found.
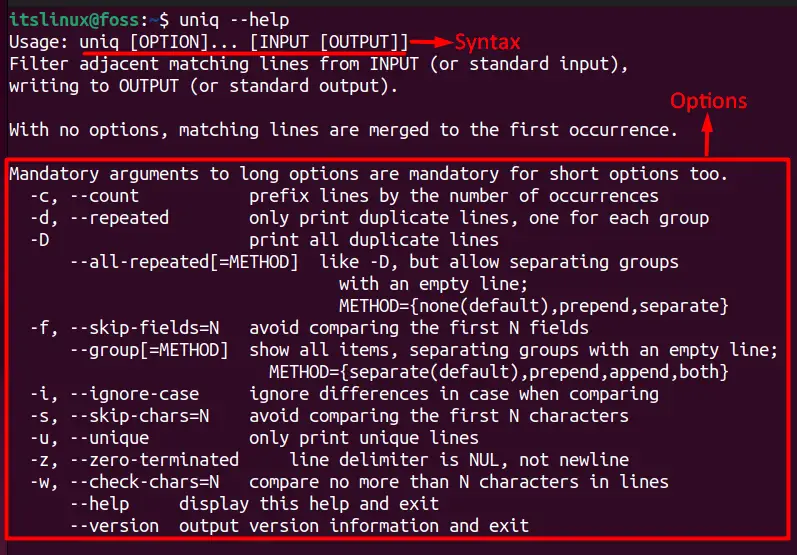
The basic “syntax” of the uniq command can be seen below:
$ sort -o <Sorted-File-Name> <File-Name-To-Be-Sorted>
How to Use the uniq Command in Linux?
This section demonstrates the usage of the uniq command through a list of examples. Let’s have a look at what the sorted data looks like.
These commands are tested on Ubuntu, Fedora, and Debian.
$ sort -o <Sorted-File-Name> <File-Name-To-Be-Sorted>
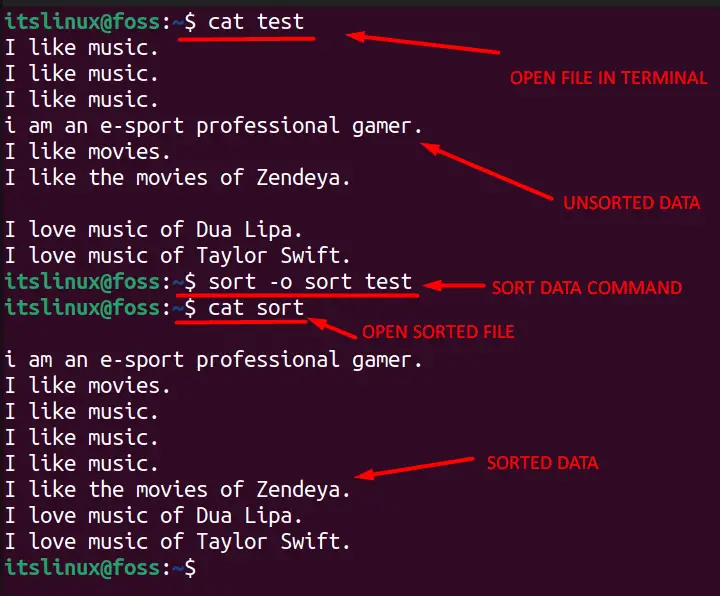
In the above image, the “-o” is used to create a new file with the same data, while “Sorted-file-name” is the name of the file you’re making, and “File-name-to-be-sorted” is the original file. We’ve named our sorted file as sort, to be precise.
Example 1: Count the Number of Repeated Lines Using uniq
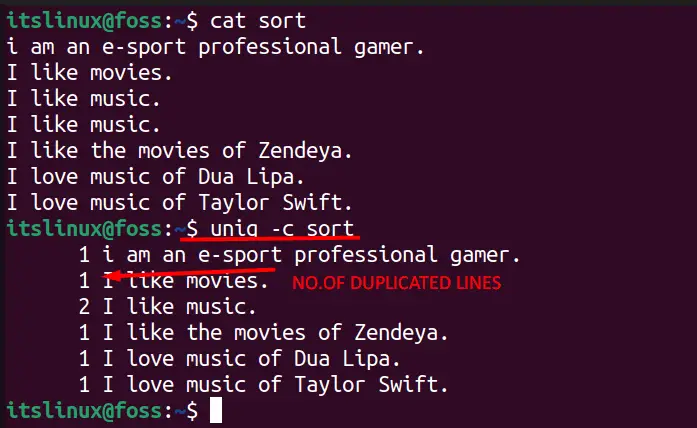
Some users would need to count the number of duplicate entries in the data, which can be done by using this command in the following syntax.
$ uniq -c <File-Name>
It can be seen in the image below that it has assigned a number that represents how many times a specific line is repeated.
Example 2: View Only the Repeated Lines Using uniq
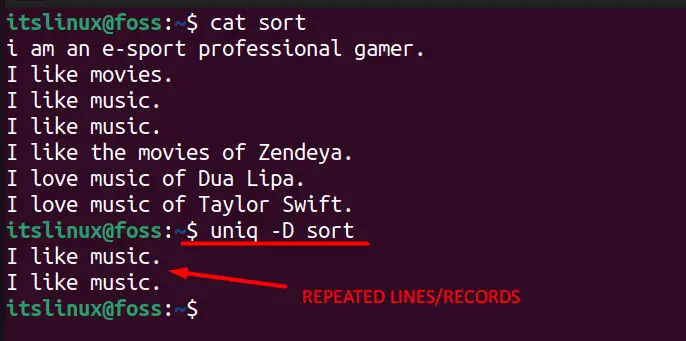
Using the uniq command, users can view all the repeated/duplicated entries in the file using the following command.
$ uniq -D <File-Name>
You can see in the below image that only those lines now show which are repeating in the text.
$ cat sort
Example 3: View Unique Lines Ignoring Case Sensitivity
With the uniq command, filtered data is case sensitive means it will not show duplicate records like “Cat” and “cat.” You can see that these words are the same, but the terminal doesn’t know that, so we will use this command to ignore the case-sensitive nature of uniq.
$ uniq -i <File-Name>
To avoid the case sensitivity, we have used the ‘-i’ flag, and you can see it is now considering both lines, including small and capital letters:
$ uniq sort
$ uniq -i sort
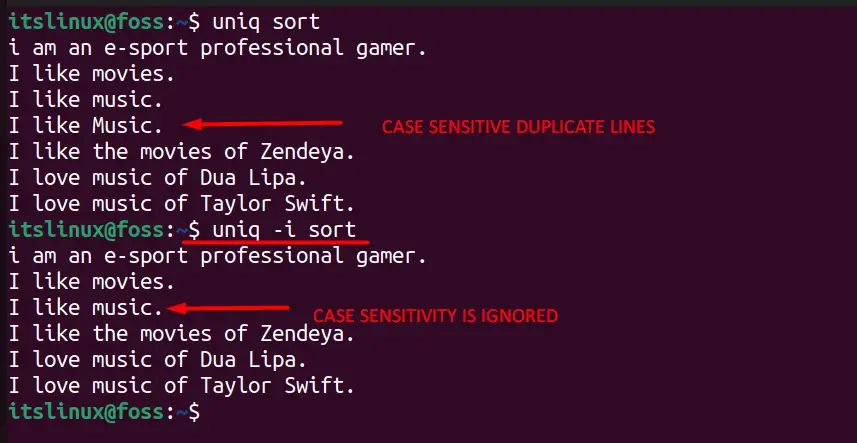
In the above image, you can see that we’ve first used a simple uniq command that didn’t ignore case-sensitive repetitions, but it is not ignored in the second command.
Example 4: View Non-Repeated Lines
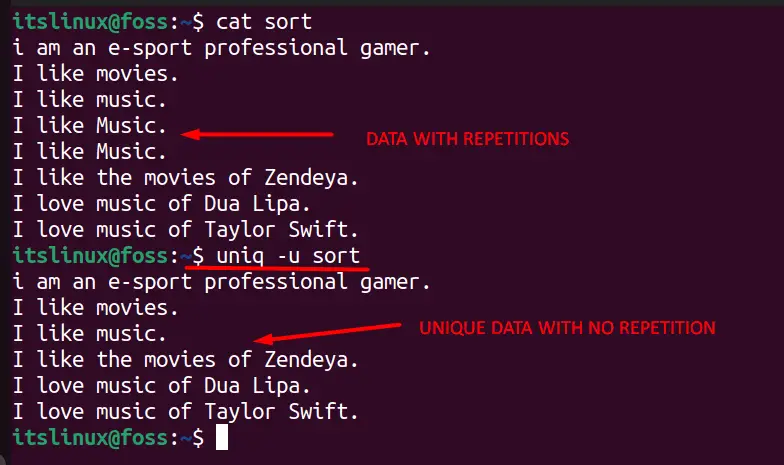
Filtering out the unique records or lines from the data is one of the most desired things from the users who work with text; it can be done using the uniq command as in this syntax:
$ uniq -u <File-Name>
It can be seen in the below image that it removed all the repeated lines and now only unique text is showing.
$ cat sort
$ uniq -u sort
Example 5: Skip Fields to Filter Duplicate Lines
Some users would wish to ignore the few letters (fields) to filter the text, which is an easy task while using the uniq command. It can be done in this syntax:
$ uniq <No.of-Fields-To-Skip> <File-Name>
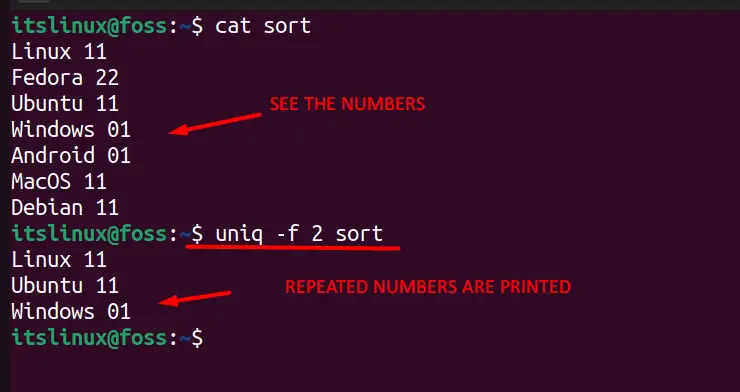
In the below image, we can see that there is no repetition of “Alphabets,” but there are duplications of numbers. So we used the “skip fields” command to print the repeated entries based on the second field, and ‘2’ in the command represents the second column.
$ cat sort
$ uniq -f 2 sort
Example 6: Skip Characters to Filter Duplicate Lines
Now, if the users want to skip the characters that they don’t want to be filtered using this command, they can skip the first characters of their choice after every line of the data.
$ uniq -s <Number-of-Characters-To-Skip> <File-Name>
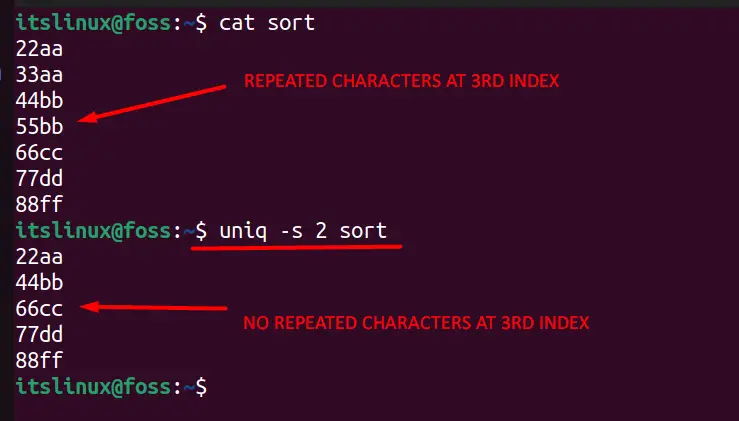
We’ve changed the data for better understanding in the below image. You can see that there are repeated characters on the 3rd index of lines 2-3, and after using the “-s” command, we’ve skipped the first two characters of them. The data isn’t the same before 3rd index, but by skipping the before part, we can filter our data.
$ cat sort
$ uniq -s 2 sort
That’s all for this article!
Conclusion
The uniq command allows the user to filter the text from any file using different flags. This command is useful for sorting the data or removing duplicate lines from the text file. You have learned the working through its syntax and the usage of the uniq command via various examples.
