
In Linux, duplicate files are those files having the same name and size in a given directory or a set of directories with identical content. There are several ways to find duplicate files and then remove them. It is beneficial to free up disk space and organize files, optimize disk usage, and streamline data management.
This guide will offer the quickest method to find duplicate files in Linux.
- What is the Quickest Way to Find Duplicate Files?
- Install the “fdupes” Package
- Find Duplicate Files
- Review and Delete Duplicate Files
What is the Quickest Way to Find Duplicate Files?
The quickest way to find duplicate files in Linux is to use the “fdupes” command. It compares files by their content and provides a list of duplicate files. After that, users can review and delete it from the operating system.
Step 1: Install the fdupes Package
The fdupes package provides a command-line tool for finding duplicate files. Users can install it using the apt package manager for Linux distribution. For example, on Debian-based systems like Ubuntu, run the following command:
$ sudo apt install fdupes # Ubuntu, Debian and LinuxMint
$ sudo yum install fdupes # CentOS/RHEL
$ sudo dnf install fdupes # Fedora
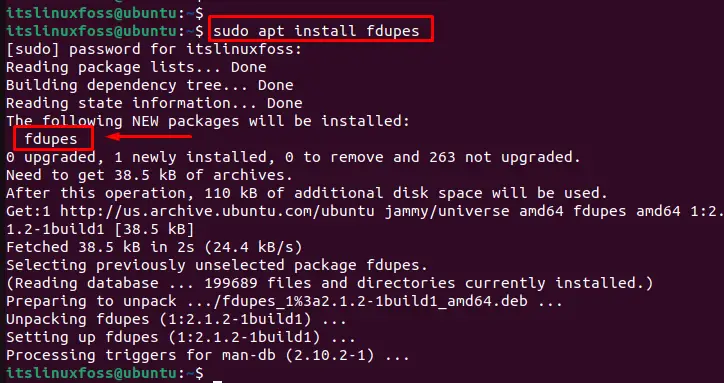
The output shows that the fdupes package has been installed in the system.
Step 2: Find Duplicate Files
Once the fdupes package is installed, run the “fdupes” command to find duplicate files with the “r” option. The “-r” option tells fdupes to search for duplicate files recursively in the specified directory such as the “/home/itslinuxfoss/Folder” directory:
$ fdupes -r /home/itslinuxfoss/Folder

This way, the fdupes command compares files by their content, not just by their names.
Step 3: Review and Delete Duplicate Files
After finding duplicate files, users can keep or delete files according to their needs. To delete duplicate files, use the “rm” command followed by the path to the file as below:
$ rm /home/itslinuxfoss/Folder/file.txt

The output shows that file.txt has been removed from the system.
Note that you should be cautious when deleting files and make sure that you are deleting the correct files. It’s a good practice to make a backup of important files before deleting them.
Conclusion
To find duplicate files in the quickest way, use the “fdupes” command with the “r” option by specifying the directory name. It displays a list of duplicated files found in the directory along with its subdirectories. Using this, users can review the list to identify which files they want to delete or keep.
This article has illustrated the quickest method to find duplicate files.
