In Python, Pandas DataFrame is arranged in a row and column structure. Every row and column in the Pandas DataFrame is represented by the label. The horizontal row label is the index, and the vertical column label is called the header. While dealing with a large dataset, some changes are carried out which modify the index of the Pandas Dataframe.
In this article, you will learn to reset the index of Pandas DataFrame in Python. The index resetting of pandas DataFrame allows us to get back the default index and also enables us to add a new index at a new column position. The content of this guide is provided below:
- How to Reset Index of Pandas DataFrame?
- Example 1: Resetting Default Index of Pandas DataFrame
- Example 2: Create and Reset User-Defined Index of Pandas DataFrame
So let’s get started!
How to Reset the Index of Pandas DataFrame?
The “DataFrame.reset_index()” is used in Python to reset the DataFrame index. By replacing the default index with a new one, this function adds a new index to a new column or the same column. The working of this function is thoroughly explained using its syntax:
| DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=”) |
In the above syntax:
- The first parameter named “level” specifies the position of the Row Index of DataFrame when there are multiple DataFrame presents in the program.
- The second parameter, “drop”, takes the boolean value as an input “True or False”. The true value returns the actual row index to a new column, while the false value will add the current row index to a new column.
- By default, the “inplace” parameter value is “False”. This parameter returns a new DataFrame when the value is “True” and updates an existing DataFrame when the value is “False”.
- The “col_level” parameter and “col_fill” parameter are used in multi-level DataFrame.
Example 1: Resetting Default Index of Pandas DataFrame
In the following code, the index sequence is first created, removed, and finally reset to its default value. Let’s understand it with the code given below:
Code:
import pandas as pd
import numpy as np
students = {'name': ['Alex', 'Henry', 'John','Lily', 'David'],
'age': [18, 14, 13, 43,18]}
data = pd.DataFrame(students)
print("Original DataFrame of Students :")
print(data)
# dropping the index number 0,1
data = data.drop([0, 1])
print("\nDataFrame after removing the row")
print(data)
data = data.reset_index()
print("\nDataframe after resetting the index")
print(data)
In the above example:
- Firstly, two important libraries of Python named “pandas” and “numPy” are imported.
- The dictionary value is initialized in the program by defining values to its key and stored in a variable named “students”.
- The “pd.dataframe()” function converts the dictionary value into DataFrame by taking the dictionary value as an argument.
- After creating the DataFrame, we removed two rows having index values “0”and “1” using the function named “df.drop()”.
- After removing the rows, the index numbers of DataFrame are irregular; for example, the index number starts from 2 instead of 0.
- To reset the index number, the “data.reset_index()” function is used in the program. After calling this function, DataFrame values are arranged in the default index value.
Output:
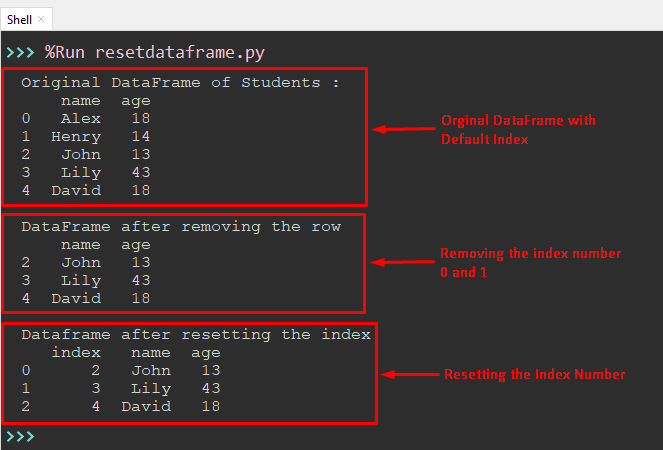
The output shows three different DataFrame, the first DataFrame is original without any changes, and the second DataFrame has no 0 and 1 index. In the third DataFrame, the index value is reset to the default index number.
Example 2: Create and Reset User-Defined Index of Pandas DataFrame
In this example, we are creating our own index and arranging the DataFrame according to that index. The own index is reset to its default index using the “pd.reset()” function with the parameter value. Lets understand it with an example given below:
Code:
import pandas as pd
students = {'name': ['Alex', 'Henry', 'John','Lily', 'David'],
'age': [18, 14, 13, 43,18]}
student_data = pd.DataFrame(students, index=['a', 'b', 'c','d','e'])
print(student_data)
student_data = student_data.reset_index(drop=True)
print('\n',student_data)
In the following code:
- The “pandas” library is imported in the program.
- The dictionary value is initialized and stored in the variable named “students”.
- The “DataFrame” is created using the function “pd.DataFrame()”.
- The “pd.DataFrame()” contains two parameters: the first parameter takes the value of the dictionary and the second parameter takes the value of the index sequence in the form of a list.
- To reset the value of the index, the “pd.reset_index()” function is used. The parameter “drop=True” will not create a new column for the default index. The default index value is replaced by the user index.
Output:

In the above output, the user-defined index number is reset and replaced by the default index of the DataFrame.
That’s all from this guide!
Conclusion
In Python, the “DataFrame.reset_index()” is used to reset the index of pandas DataFrame. The index of DataFrame is arranged according to the default index and the user-defined index value. The new index is created and replaced with the default index using the parameter value of the “df.reset_index()” function. This Python guide has demonstrated the possible method and its relevant examples to reset the index of Pandas DataFrame.
