
Python pandas dataframe is a 2-D heterogeneous data structure organized and labeled as rows and columns. A dataframe in Python comprises multiple rows and columns. Whenever we deal with data in Python, there are a variety of operations we need to perform on that data. This write-up will provide a detailed overview to add or insert rows to Pandas DataFrame. The following aspects are discussed in this post:
- What is Pandas DataFrame?
- Method 1: Using append() Function
- Method 2: Using DataFrame.loc
- Method 3: Using pandas.concat()
So, let’s get started!
What is Pandas DataFrame?
Dataframe is the structure of data that is placed in a 2-Dimensional table of rows and columns. Pandas is a Python library used to read and write on many data file formats such as CSV, SQL, etc. To use the Pandas library in Python, we must make sure that the library is installed in our system or not.
To install the “Pandas” library on a PC, open the “Windows Powershell” and run the following command:
> pip install pandas
After installation, the users can add or insert a row to any pandas dataframe using the Python compiler. Let’s discuss different methods one by one regarding “How to add rows to Pandas DataFrame”.
Method 1: Using append() Function
The built-in “append()” function places the new elements on the available space. The “append()” function inserts the new row into the pandas DataFrame. Let’s see it via an example of code given below:
Code:
import pandas as pd
data_value = {'name': ['Alex', 'Charles', 'Mary', 'John'],
'Age': [18, 27, 22, 19],
'height': [5.2, 6.1, 4.5, 7],
'weight': [44, 48, 55, 68]}
dataframe_1 = pd.DataFrame(data_value)
print('DataFrame before Adding Row\n------------------')
print(dataframe_1)
new_value = {'name':'Lily', 'Age':17, 'height':6.3, 'weight':49}
#using append() function to add row
dataframe_1 = dataframe_1.append(new_value, ignore_index=True)
print('\n\nDataFrame after Adding Row\n--------------------------')
print(dataframe_1)
In the above code:
- The “pandas” library is imported at the beginning of the program.
- The dictionary value is initialized in the variable named “data_value”.
- The “DataFrame()” function creates the 2-D dataframe by taking the variable value named “data_value” as an input argument.
- The new dictionary variable is initialized in the variable named “new_value”.
- The “append()” function adds the new value at the bottom of the original DataFrame value named “data_value”.
- The “ignore_index” value must be “True”; otherwise, when it becomes “False”, there is a memory error on the output.
- The final output, including the new row, is printed on the console.
Output:
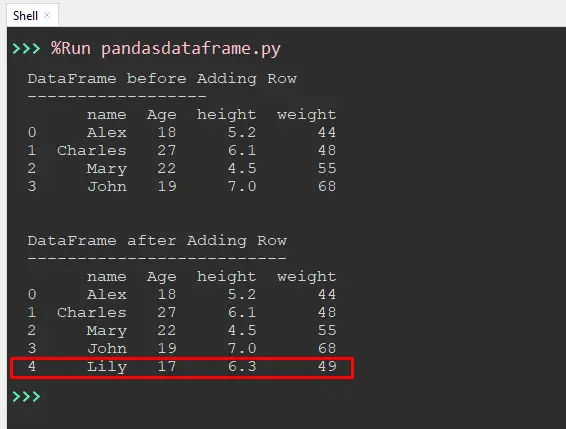
In the above output, a “new row” is inserted on the pandas DataFrame.
Method 2: Using DataFrame.loc
The “dataframe.loc” is used to add the row at the end of the original dataframe. The “len(dataframe.loc)” indicates the position of already created rows and inserts the new row at the bottom of the last row. Following is a code example to illustrate this method:
Code:
#using Dataframe.loc
import pandas as pd
data_value = {'Name':['Alex', 'Charles', 'Mary', 'John'],
'Age':[47, 19, 17, 45],
'height':[5.3, 5.9, 5.4, 6.2]
}
dataframe_1 = pd.DataFrame(data_value)
print(dataframe_1)
dataframe_1.loc[len(dataframe_1.index)] = ['Lily', 19, 6.5]
print('\n\n',dataframe_1)
In the above code:
- The “pandas” library is imported at the beginning of the program.
- The dictionary value is initialized in the variable named “data_value”, having attributes “Name”, “Age”, and “height”.
- The “pd.dataframe()” takes the variable value named “data_value” as an input and returns the 2D-pandas dataframe.
- The “dataframe.loc” attributes add the new row at the end. The function “len()” inside the parentheses of “dataframe.loc” specifies the position where the new row will be inserted.
Output:
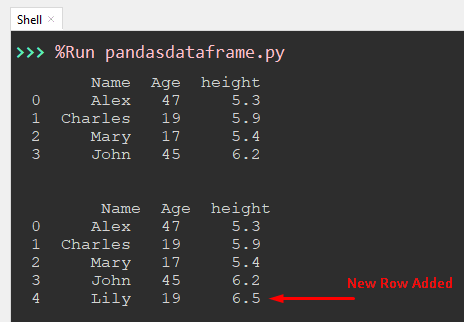
In the above output, the new row is added to the dataframe.
Method 3: Using pandas.concat()
The “pandas.concat()” function concatenates two dataframes and produces one combined final dataframe. To add the new row using “pandas.concat()”, we placed the new row into the dataframe and then combined it with the original dataframe. Let’s understand it via the following code:
Code:
import pandas as pd
data_value = {'Name':['Alex', 'Charles', 'Mary', 'John'],
'Age':[17, 11, 17, 15],
'height':[5.3, 5.9, 5.8, 5.7]}
dataframe_1 = pd.DataFrame(data_value)
print(dataframe_1)
data_value = {'Name':['Lily', 'Henry'],'Age':[19, 20],
'height':[5.4, 6.1] }
dataframe_2 = pd.DataFrame(data_value)
dataframe_3 = pd.concat([dataframe_1, dataframe_2], ignore_index = True)
print('\n\n',dataframe_3)
In the above output:
- The “pandas” library is imported at the beginning of the program.
- The dictionary value is initialized in the variable named “data_value”.
- The “pd.dataframe()” is used to create the “pandas dataframe”.
- The new dictionary variable is initialized in the variable named “new_value”.
- The “pd.dataframe()” is again used to create the new “pandas dataframe” for the new dictionary values.
- Both dataframes are concatenated using the “pd.concat()” function, and the “ignore_index=True” is passed into the second parameter of the “pd.concat” function.
- The final concatenated dataframe result is printed on the screen.
Output:
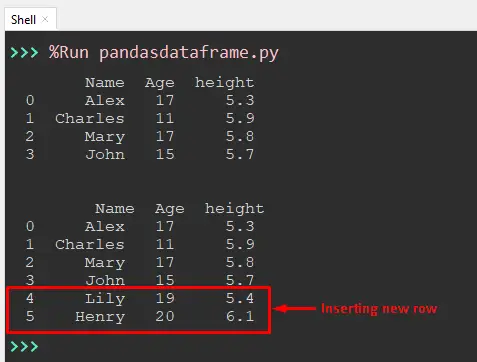
The output shows that two rows are inserted into the pandas dataframe.
That’s all from this Python guide!
Conclusion
In Python, “append()”, “DataFrame.loc”, and the “pandas.concat()” functions are used to add or insert rows to pandas DataFrame. The “append()” function is used to add the new row at the bottom of the original dataframe by taking the value of the new row and “ignore.index” as an argument. The “DataFrame.loc” attributes of pandas append the new row at the end of the original data by calculating the index number. The “pandas.concat()” function concat two dataframes and inserts the new row. This article briefly explained all the methods used to add rows in the pandas dataframe.
