As we all know, whitespaces separate the text locks to increase the text readability and make it clean and tidy. These whitespaces may be leading (at the beginning of the text), trailing (at the end of the text), tabs, or line breaks. The use of the whitespaces relies on the text requirements. If they are used improperly in a text, then it destroys the text formatting. Similar to this, the removal of whitespaces is also important in Linux to format the source code, clean the content, and simplify the command line output.
Quick Outline
- What is the sed Command in Linux?
- How to Display All Whitespaces(Including Spaces and Tabs) in Linux?
- How Does the “sed” Command Remove Whitespaces in Linux?
- What are the Alternatives of the “sed” Command to Remove Whitespaces in Linux?
Let’s first start with the basics of the “sed” command in Linux.
What is the sed Command in Linux?
In Linux, the “sed” is an acronym for “stream editor”. It is a common line utility that directly edits the files (text, binary, source code) as streams using a single command. However, the user does not need to open and edit it manually in any text editor. That’s why it is the most recommended and simplest way of editing files. Its common features include search and replace, insert, delete, and substitute.
In this scenario, it is utilized to remove whitespaces from the text. Let’s start with its practical implementation.
How to Display All Whitespaces(Including Spaces and Tabs) in Linux?
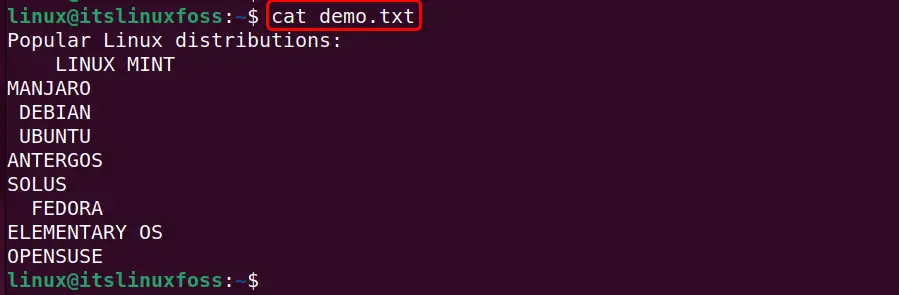
First, execute the “cat” command to check the whitespaces including both leading, trailing, and the tabs in a text file:
cat demo.txt
The execution of the simplest “cat” command displays all the spaces as a whitespace like this:
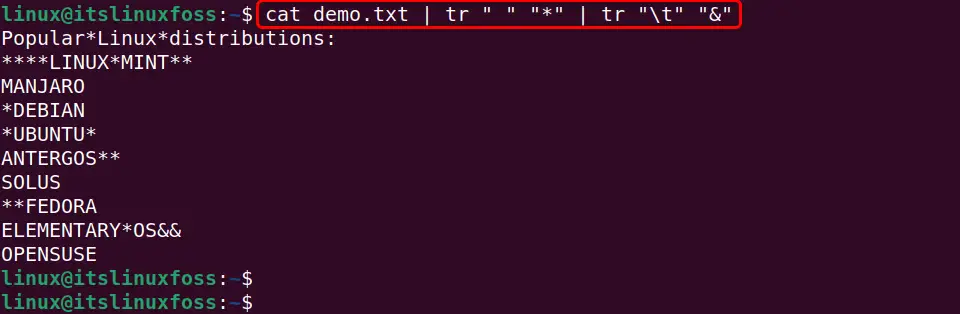
For better demonstration, concatenate the “cat” and the “tr” command using the “|(Pipe character)” in this way:
cat demo.txt | tr " " "*" | tr "\t" "&"
In the above code block, the first “tr” command replaces the leading and trailing spaces with “*(asterisk)” and “\t” tab spaces with “&(Ampersand Operator)”.
Output
The output clearly represents the leading and trailing spaces with “*” and “\t” tab spaces with “&”:
Note: All the whitespaces can also be replaced by other special characters like “!”, “/”, “@”, “%”, and many others.
How Does the “sed” Command Remove Whitespaces in Linux?
The “sed” command removes the whitespaces from text files using its subcommands, supported options, and regular expressions. This section carries its practical implementation with the help of the below-stated examples.
Example 1: Use the “sed” Command to Remove All Leading Whitespaces
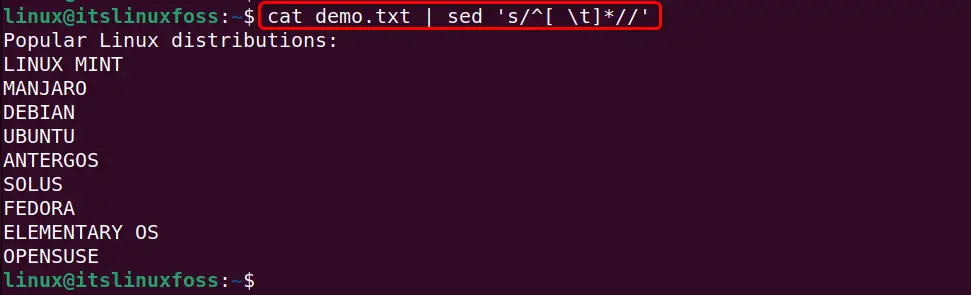
The first example removes all the leading whitespaces including tabs using the below-stated “sed” command and then displays the modified text in the terminal:
cat demo.txt | sed 's/^[ \t]*//'
In the above command:
- The “|(Pipe)” character takes the input of the “cat” command and forwards it to the “sed” to remove the whitespace of the specified file.
- The “s” subcommand replaces the specified “\t” tab and the “*” leading spaces with nothing “//” from the specified input file.
- The “^(hat)” symbol specifies the beginning of each line.
Output
It can be observed that all the whitespaces have been removed from the input file:
Save the Changes in the Original File
One important thing to keep in mind is that the above changes only happened at run time on the terminal, not in the original text file.
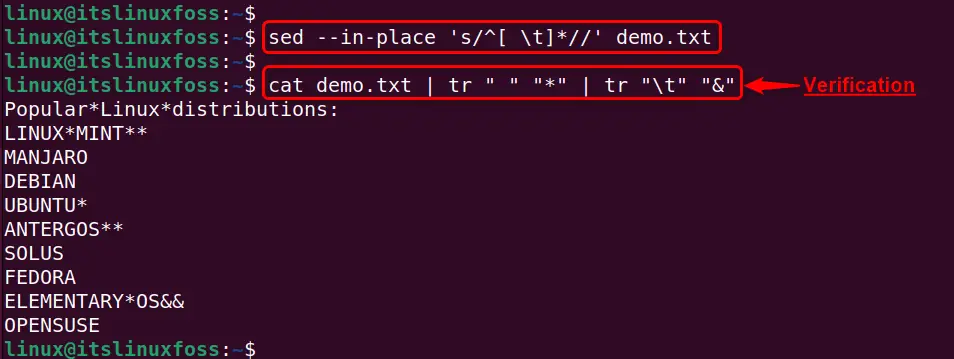
To save those changes in the actual file use the “–in-place” supported option along with the above “sed” command like this:
sed --in-place 's/^[ \t]*//' demo.txt
cat demo.txt | tr " " "*" | tr "\t" "&"
Output
The execution of the above commands verifies that all the leading whitespaces and tabs have been removed from the specified file permanently:
Example 2: Use the “sed” Command to Remove the Leading Whitespaces From the Specific Lines
In this example, the “sed” command removes the leading whitespaces and tabs from the specific line, not from the whole text file:
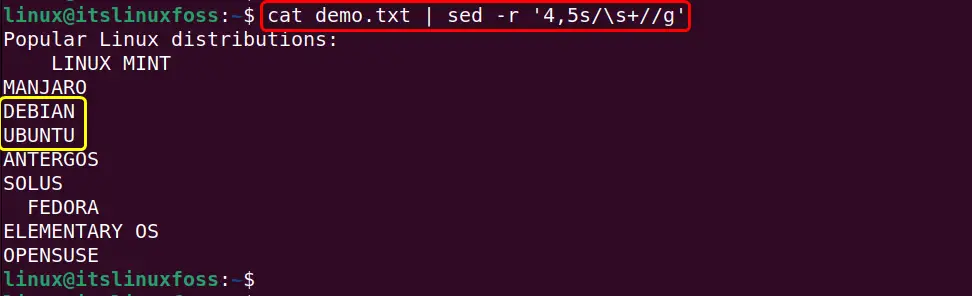
cat demo.txt | sed -r '4,5s/\s+//g'
In the above command:
- The “-r” supported option allows the “sed” command to utilize the specified extended regular expressions.
- The “4,5” denotes the line number from which the leading whitespaces and tabs must be removed.
- The “s+” matches more than one whitespace character and removes them globally(g) from the input file.
Output
The output shows the removal of leading whitespaces and tabs from the specified line:
Example 3: Use the “sed” Command to Remove All Trailing Whitespaces
This example utilizes the “sed” command to remove all the trailing whitespaces and tabs from the input file temporarily:
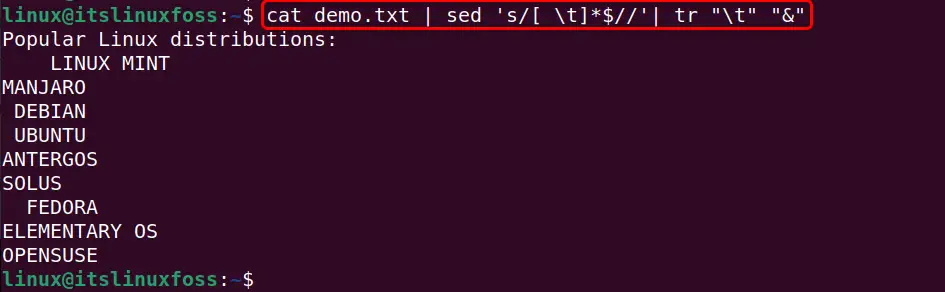
cat demo.txt | sed 's/[ \t]*$//'| tr "\t" "&"
In the above command, the “$” denotes the end of each line.
Output
It can be verified that after the execution of the above command no trailing whitespace and tabs are left in the given input file
Example 4: Use the “sed” Command to Remove the Trailing Whitespaces From the Specific Line
Like the leading whitespaces, the “sed” command removes the trailing whitespaces from the line of a file. For this purpose, specify the line number along with the substitution subcommand in this way:
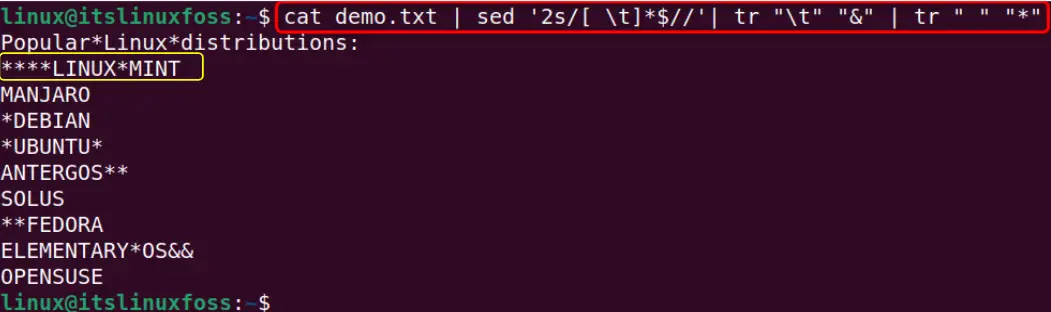
cat demo.txt | sed '2s/[ \t]*$//'| tr "\t" "&" | tr " " "*"
Output
Here, the output confirms that trailing spaces have been removed successfully from the specified line of an input file:
Example 5: Use the “sed” Command to Remove Both Leading and Trailing Whitespaces
This example combines the removal of both leading and trailing whitespace commands to remove all the whitespaces and tabs at a time from the text:
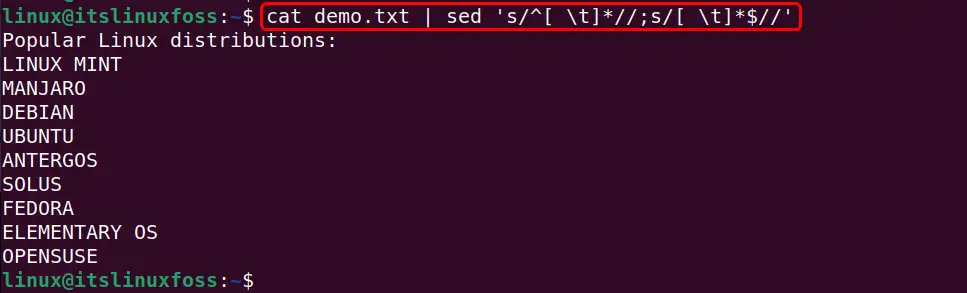
cat demo.txt | sed 's/^[ \t]*//;s/[ \t]*$//'
Output
The below output verifies that both leading and trailing whitespaces have been removed from the given text file successfully:
Example 6: Use the “sed” Command to Remove All Whitespace (Leading, Trailing and Between Text)
As we know, the single space between each word plays an important role in the readability of text. If the user wants to remove all the whitespaces including that single space between text, then execute this “sed” command:
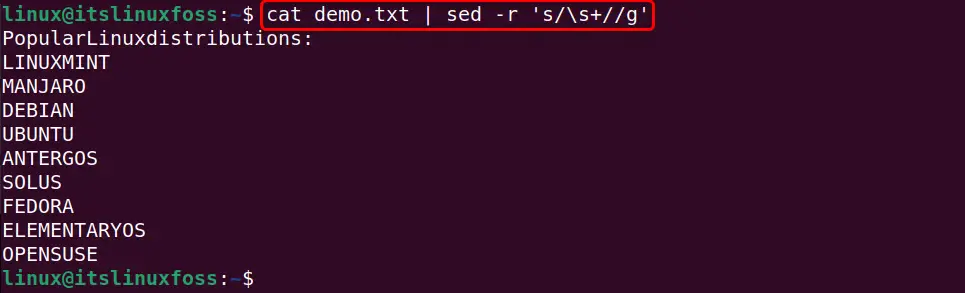
cat demo.txt | sed -r 's/\s+//g'
In the above command, there are no “^” and “$” characters because in this scenario all the whitespaces will be removed.
Output
In the given output all whitespaces from the start end, and between the text have been removed:
Example 7: Use the “sed” Command to Remove White Spaces Included as Blank Lines
The whitespaces may also include blank lines that can be easily removed with the help of the “sed” command.
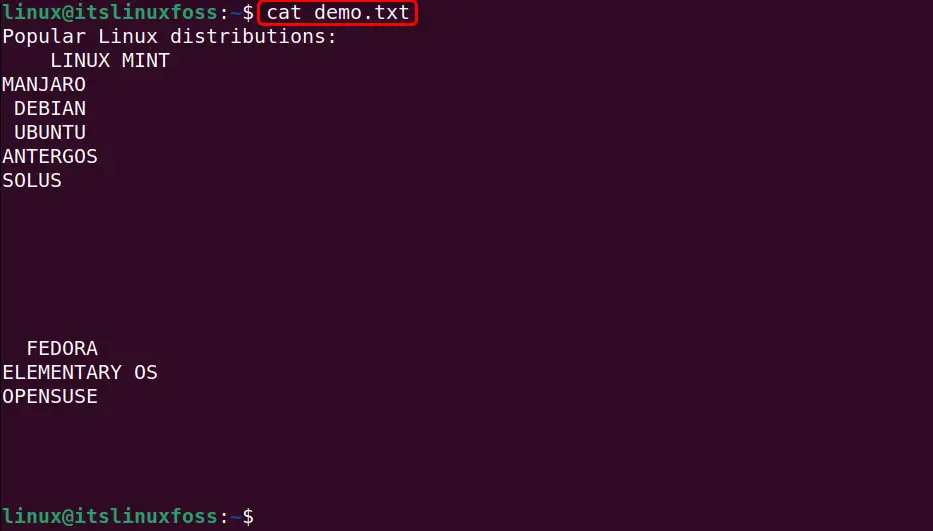
This example first executes the “cat” command to look at the input file that contains blank lines:
cat demo.txt
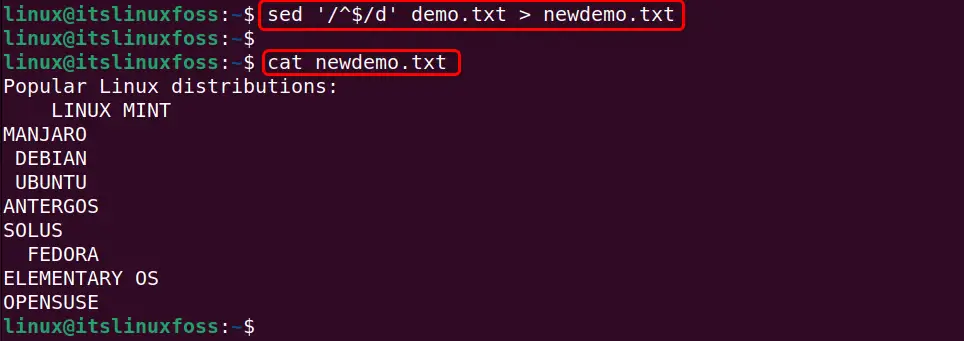
Next, it runs the “sed” command to remove all the blank lines from the input file and save the updated content into a new file. After that, it executes the “cat” command for confirmation:
sed '/^$/d' demo.txt > newdemo.txtcat newdemo.txt
In the above command:
- The “d” subcommand “deletes” the blank lines from the start(^) and end($) of each line.
- The “>(redirection)” operator redirects the output of the “sed” command to the given “newdemo.txt” text file.
Output
It can be observed that the “sed” command executed successfully and saves the modified content into a new automatically generated “newdemo.txt” file:
Example 8: Use the “sed” Command to Replace All Whitespaces With a Single Space
Apart from removing the multiple white and tab spaces, the user replaces them with a single space using the “sed” command. It makes the content of the text file neat and clean.
This example performs the above-defined functionality with or without tab spaces. Let’s first start with the excluding tab spaces use-case.
Excluding Tab Spaces
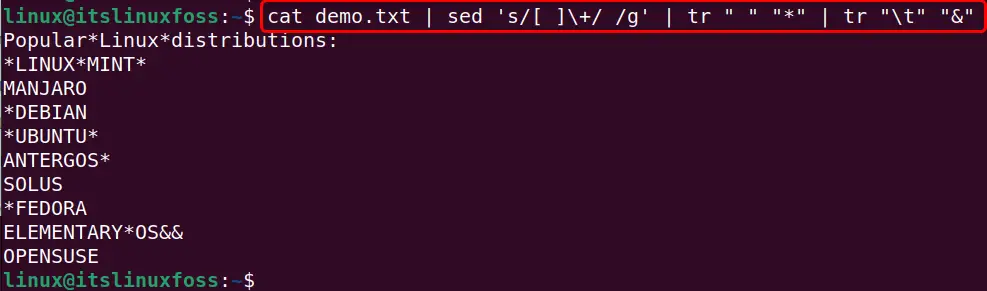
To replace all whitespaces excluding tab spaces, execute the below-stated “sed” command:
cat demo.txt | sed 's/[ ]\+/ /g' | tr " " "*" | tr "\t" "&"
In the above “sed” command, the “[ ]” denotes both leading and trailing whitespaces that will be replaced with the “/ /” single whitespace globally(g):
Output
All the whitespace has been replaced with a single whitespace excluding the tab spaces:
Including Tab Spaces
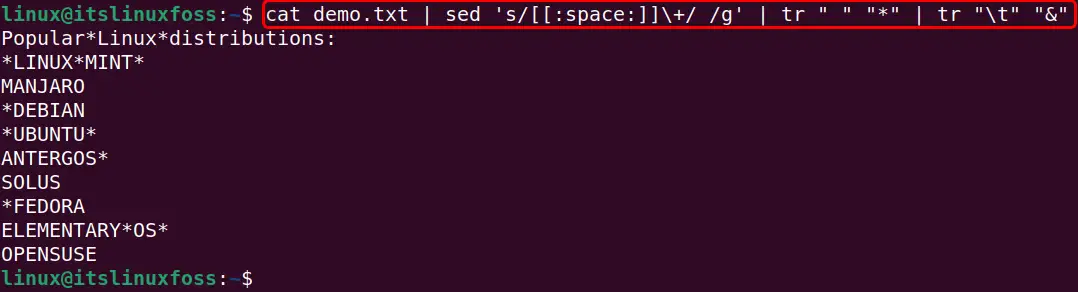
To remove all the whitespaces including the tab spaces specify the “[:space:]” sub-expression with the “sed” command that refers to the zero or more spaces in a text:
cat demo.txt | sed 's/[[:space:]]\+/ /g' | tr " " "*" | tr "\t" "&"
Output
Now, the output shows that all the whitespaces including tabs have been replaced with a single whitespace:
Note: If the user wants to remove the consecutive whitespaces from the text file using the “sed” command then read our detailed guide on “sed Command | sed ‘s/\s\s*/ /g’”.
What are the Alternatives of the “sed” Command to Remove Whitespaces in Linux?
The same above-defined functionality (removal of whitespaces) can also be achieved with the help of the below-stated built-in Linux command:
- Alternative 1: Remove Whitespaces Using “awk” Command
- Alternative 2: Remove Whitespaces Using “tr” Command
- Alternative 3: Remove Whitespaces Using “grep” Command
Let’s first start with the Linux “awk” command.
Alternative 1: Remove Whitespaces Using the “awk” Command
Linux “awk” command is another utility that searches the particular pattern from the text and replaces it with the specified one. It is used for text processing the same as the “sed” command line utility. In this scenario, it is utilized to remove all whitespaces from the text.
Here is its practical implementation:
cat demo.txt | awk '{ gsub(/^[ \t]+|[ \t]+$/, ""); print }'
In the above command:
- The “gsub()” function replaces all occurrences of the matched pattern with the specified one in the actual file.
- Inside the “gsub()” function the “^[ \t]” denotes the white and tabs spaces at the start of each line and the “[\t]+$” refers to the spaces both white and tabs at the end of each line.
- Next, the “(double-quotes)” denotes the single whitespace.
- Lastly, the “print” statement prints the output on the terminal.
Output
The output confirms that all the leading and trailing whites + tab spaces have been removed from the given text file:
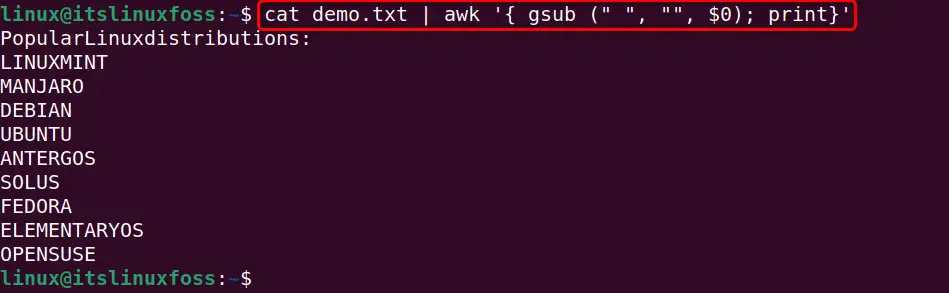
Moreover, the “awk” command can also be utilized to remove the single whitespaces between the text in this way:
cat demo.txt | awk '{ gsub (" ", "", $0); print}'
In this scenario the “awk” command does not specify the starting, ending and tab spaces characters in the “gsub()” function. This is because now each whitespace will be removed from the whole($0) lines of the text file.
Output
It can be observed that in this output each whitespace has been removed and now there is no white and tabs space even between the text:
Alternative 2: Remove Whitespaces Using the “tr” Command
Linux offers “tr” command to edit the text in multiple ways like search and replacement, squeezing repeated characters, case conversion, and much more. In this section, it is utilized to remove whitespaces from the text.
The below command shows its practical implementation:
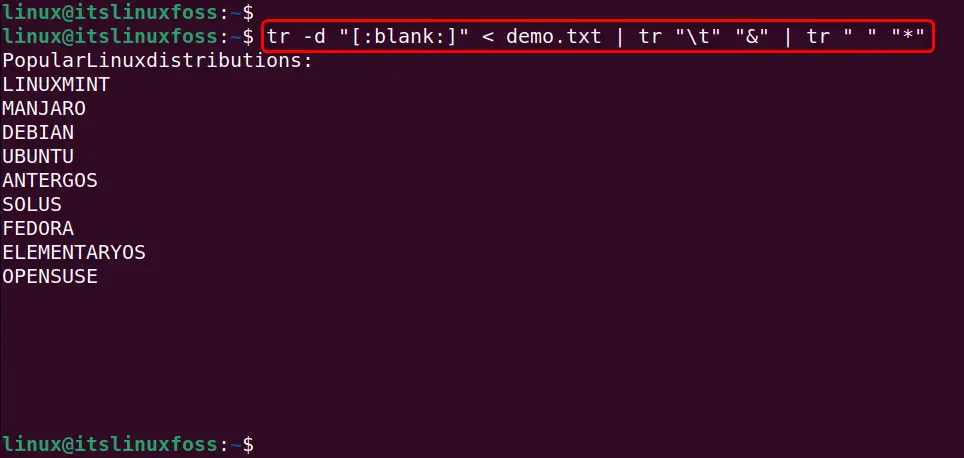
tr -d "[:blank:]" < demo.txt | tr "\t" "&" | tr " " "*"
In the above code block, the “-d” flag tells the “tr” command to delete the group “[:blank:]” of spaces (Leading, Trailing, Tab, Between) and tab characters from the input file. After that, it shows the modified content on the terminal.
Output
The below output shows the updated content of the sample file in which all whitespaces, not the blank lines have been removed successfully:
In addition, to remove all whitespaces including “blank” lines specify the “[:space:]” text search pattern along with the “tr” command in this way:
tr -d "[:space:]" < demo.txt
Output
Now, all the whitespaces including blank and new lines have been removed from the input file:
Alternative 3: Remove Whitespaces Using the “grep” Command
Another text manipulation command line utility in Linux is “grep”. It searches the string of characters from the text file. However, it does not replace the matched pattern with the new one. That’s why it can only be utilized to remove blank lines from the file, not the other whitespaces (leading, trailing, and tabs).
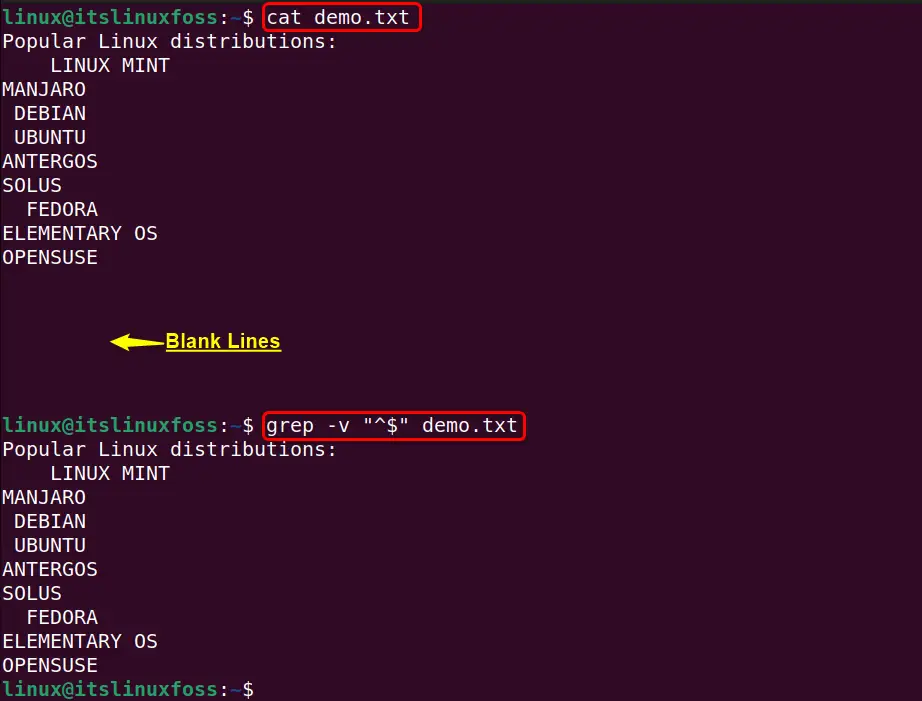
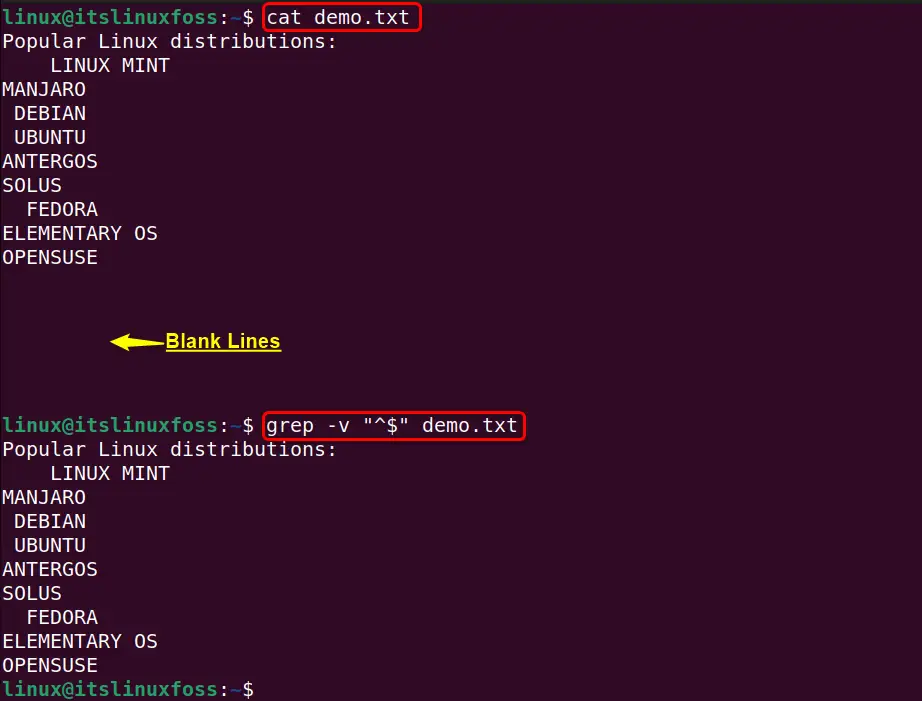
As an example, a sample file is displayed via the “cat” command in the terminal that contains multiple blank lines at its end:
cat demo.txt
To remove all blank lines from the above sample file, execute the below-stated “grep” command:
grep -v "^$" demo.txt
In the above command, the “-v” flag tells the “grep” command to print each line from the given text file that does not match with the “^$” pattern. This pattern specifies the line that starts and ends with nothing such as blank lines.
Output
It can be analyzed that the execution of the “grep” command removes all the blank lines from the given input file:
That’s all about the sed command to remove whitespaces in Linux.
Conclusion
In Linux, the “sed” command removes the whitespaces from text files with the combination of its subcommands, supported options, and regular expressions. It can be used to remove both leading and trailing whitespaces including the tab spaces at the same time or separately.
In addition, this task can also be achieved via the Linux “awk” and “tr” commands. Furthermore, if the user wants to remove only blank lines from the text files, then both the “sed” or the “grep” commands can be utilized. This guide has deeply explained how the sed command removes whitespaces in Linux.
