File handling plays a significant role in programmers’ lives as it allows them to preserve and access a large amount of data from the users. These files may be of any type like text, configuration, or binary. In Linux, all these files can be easily handled through the default editors like Nano or Vim based on the Linux distribution.
Moreover, the user can also edit and manage those files using another well-reputed built-in command line utility “sed”. It takes the input file as a stream, accesses its content as a captured group, and edits it through the command.
Quick Outline
- What is the “sed” Command in Linux?
- What Does “sed” Capture Groups Mean?
- How to Use the “sed” Command to Capture Groups in Linux?
Let’s first start with the basics of the “sed” command in Linux.
What is the “sed” Command in Linux?
The “sed” command is an acronym for “stream editor” in Linux. It acts as a command line editor that edits files instantly in the terminal by executing one-line commands. In addition, the user does not have to open and edit files manually on the text editor.
Its common features are search, replace, insert, delete, and substitute. Its most common feature is to “search/find” the text from the file and “replace” it with the specified one. This command line utility works on “RegExp” to perform pattern-matching tasks.
What Does “sed” Capture Groups Mean?
The “capture groups” is a convenient, and well-reputed feature of the “sed” command that provides access to a specific part of the text file or a line. Once the specified part of the text file or line is accessed, the user can perform multiple editing operations on it. These operations include replace, delete, insert, modify, and much more.
The objective of sed Captured Groups
The main objective is to “retrieve” the required information from the text. Moreover, it also “manipulates” the captured group based on the requirements.
After getting the basics of the “capture groups”, let’s manipulate them in different ways with the help of the “sed” command.
How to Use the “sed” Command to Capture Groups in Linux?
The creation of a “capture group” using the “sed” command is quite simple. It only requires capturing parentheses along with the backward slash like “\(” at the start and “\)” at the end of the group(a specific part of the text). After that specify the subcommands or regex to perform the editing operation on it.
This section covers basic to advanced-level examples to capture the groups using the “sed” command and then manipulate them based on the requirements.
Example 1: Use the “sed” Command to Replace a Single Captured Group From a Line
This example utilizes the “sed” command to capture the single group from the line and then replace it with the desired one:
echo Welcome to Linux sed! | sed 's/\(Linux\) sed!/\1 itsLinuxFOSS/'
The description of the above command is as follows:
- The “echo” command displays the specified line into the terminal.
- The “sed!” command preceded by the “exclamation mark(!)” affects the no matches specified as an address.
- The “pipe(|)” takes the output of the “echo” command and refers to it as an input of the “sed” command.
- The “sed” command first uses the “s(substitute)” option to match the specified pattern. It performs the searching process based on a given no of pattern occurrences in the input line.
- Next, it captures the specified string from the input line as a “capture group” and replaces it with the content written at the end of the command.
Output
It can be analyzed that the sed capture the word “Linux” and then replace the word occurring after it (“sed!”) with “itsLinuxFOSS”:

Example 2: Use the “sed” Command to Parse a Single Captured Group From a File
This example utilizes the “sed” command to parse the value of a specific key as a single captured group from a JSON file.
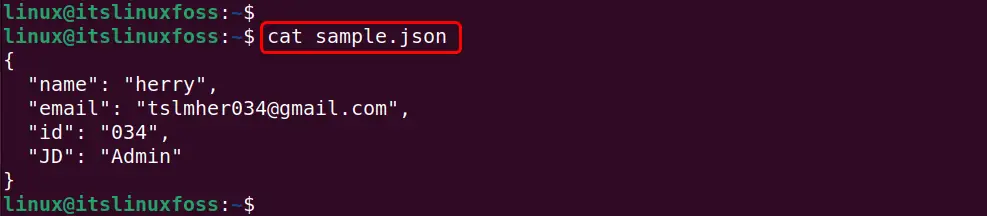
First look at the sample JSON file in the terminal using the “cat command”:
cat sample.json
Next, parse a single captured group from the above JSON file using the given “sed” command:
sed -n 's/[ \t]*"email": "\(.*\)",\?/\1/p' sample.json
In the above command:
- The “-n” displays only the matched pattern and disables the automatic printing.
- The “[\t]*” option matches one or more tabs.
- The “email” followed by “:” specifies the key whose value needs to be parsed as a single captured group.
- The “regexp(.*)” enclosed inside the (“\(” “\)”) generalized syntax denotes the actual captured group.
- Next, in the “operation(,\?/\1/p)”, the “,\?” matches the “comma(,)” by one or more times, the “\1” specifies the captured string, and the “/p” prints the matched pattern on the terminal.
Output
It can be observed that the “sed” command parsed the specified captured group:

Example 3: Use the “sed” Command to Print Multiple Captured Groups in Reverse Order
This example captures the multiple groups using the “sed” command to print them in reverse order:
echo ITSLINUXFOSS Website provides quality content on Linux | sed 's/\(ITSLINUXFOSS\) \(Website\)/\2 \1/'
In the above “sed” command:
- The (“\(” “\)”) syntax captures the multiple groups from the input line.
- The “\2”, and “\1” denote the index of the captured group in reverse order.
Output
The following output shows that the multiple captured groups are displayed in the “reverse” order without affecting the remaining strings of an input line:

Example 4: Use the “sed” Command to Capture the Complex Expressions and Reverse Them
This example deals with the complex expressions to capture them as a group and then display them on the terminal in reverse order:
echo 001 ITSLINUXFOSS Website | sed 's/\(\w\w*\) \(\w\w*\) \(\w\w*\)/\3 \2 \1/'
In the above the “sed” command followed by (“\(” “\)”) syntax uses the “\w\w*” regex to capture the specified alphanumeric([A-Za-z0-9]) keywords as a group.
Output
The “sed” command captured the specified alphanumeric complex expression as a group and displayed in reverse order:

Alternative of “\w\w*” expression
The above functionality can be achieved through the “[[:alnum:]_]\{1,\}” alphanumeric character class:
echo 001 ITSLINUXFOSS Website | sed 's/\([[:alnum:]_]\{1,\}\) \([[:alnum:]_]\{1,\}\) \([[:alnum:]_]\{1,\}\)/\3 \2 \1/'

Example 5: Use the “sed” Command to Delete Matching RegExp From the Captured Group
This example captures a group from the sample file and then deletes the matched regex from it using the “sed” command.
First, look at the sample text file via the “cat” command:
cat sampleFile.txt

Now access the specific part of the above-opened file as a captured group and remove the matched regex from it:
sed -E '/^#/n; s/(num[0-9]{3})_[0-9]/\1/g' sampleFile.txt
In the above command:
- The “-E” supported function supports the given extended regular expression.
- The “{3}” specifies the number of lines in an input file.
- The “_[0-9]” specifies any digit starting from “_(underscore)”.
Output
It can be analyzed that the content of the specified file has been modified:

That is all about using the “sed” command to capture groups in Linux.
Conclusion
To “capture groups” with the “sed” command line utility, use the “capturing parentheses” “\(” “\)”. These parentheses access the specific part of a file or line to perform different operations on it using the “sed” command. The “sed” command specifies the captured group enclosed inside the capturing parentheses. After that, it specifies the operation as a “regex” to replace, delete, modify, parse, and edit the captured group. This post has practically elaborated on how to use the “sed” command to capture groups in Linux.
